Single Style Application
DreamWalk allows fine-grained control of style text-to-image generation. We start with a base generated image (left), and apply style guidance terms with guidance scale functions to create different stylized images. Our style application works on any diffusion model regardless of architecture differences.
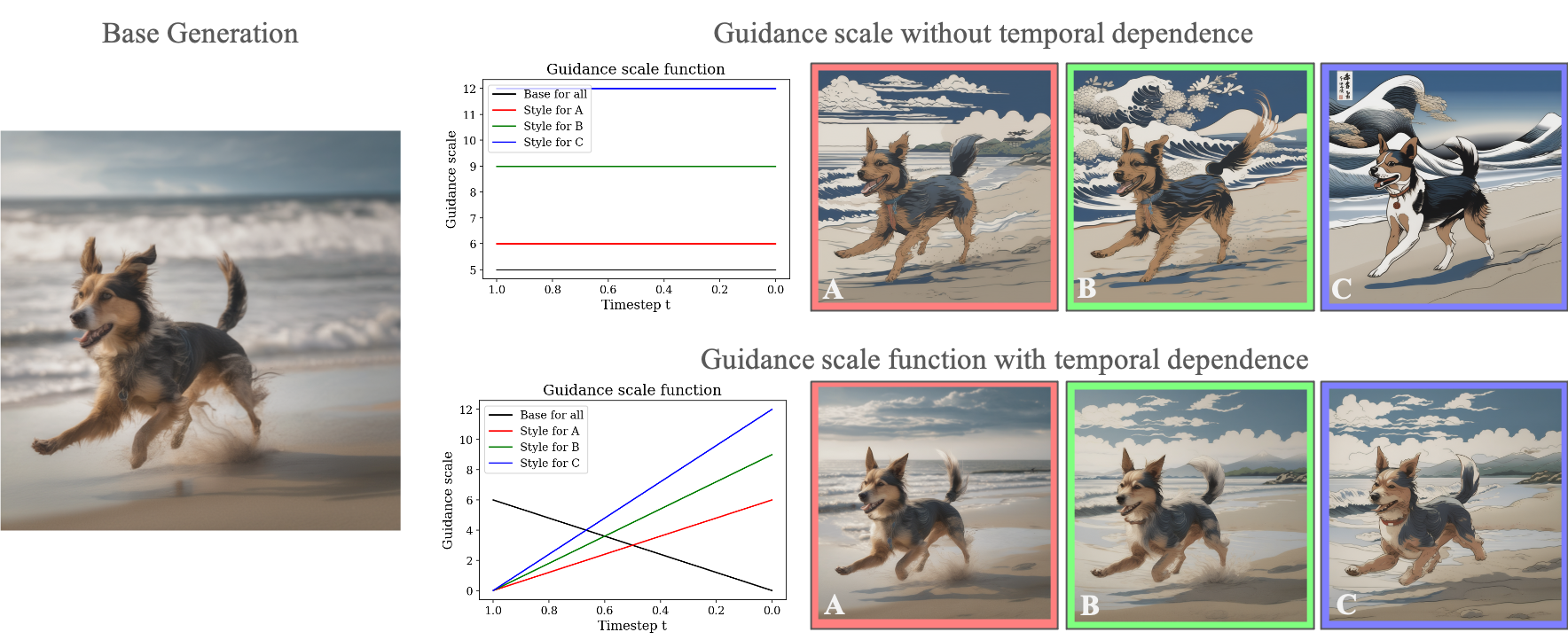
Changing the magnitude of the guidance scale has different effects based on the temporal component of guidance scale functions. Increasing the magnitude of a guidance scale without time dependence (bottom row) can change the layout of the image. Our default setting for temporal dependence preserves the rough layout of the base generation while still increasing the amount of style being added (top row).

Pixel Art

Rene Magritte

van Gogh

Picasso

Qi Baishi
"A peaceful riverside village with charming old cottages".


Rene Magritte

Hokusai
Pixel Art

Qi Baishi

Monet
"a dog running on a beach".

Pixel Art

Qi Baishi

Watercolor

Picasso
"A serene garden with a serene pond and arched bridges".
Interpolation between Styles
Our method also allows users to interpolate between multiple styles. We show that our smooth interpolation between two different styles for models with very different architectures SD1.5 and SDXL.

(SD1.5) A group of children flying kites on a breezy summer day at the park in the style of {Monet, Magritte}. First Row: CLIP embedding baseline. Second Row: Ours.

(SD1.5) A Horse galloping freely across vast open field in the style of {water color, pixel art}. First Row: CLIP embedding baseline. Second Row: Ours.

(SD1.5) Artist painting vivid sunset on beach canvas in the style of {Picasso, Hokusai}. First Row: CLIP embedding baseline. Second Row: Ours.

"Campsite with a fire at night (SDXL: Monet -> Picasso)"

"A dog running on a beach (SDXL: Monet -> Hokusai)"
Spatially Varying Guidance Function
Based on the base image, style guidance can be applied to different parts of the image. This allows users to define their own masks manually or with computed signals like bounding boxes.


"Fish swimming down a stream (SDXL: Picasso)"

"Dog running on a beach (SDXL: Monet)"

"Bird sitting on a tree branch (SDXL: Hokusai)"








